Evidence from 20 Gymnasium environments
Thibaut Kulak, Neoinstinct SA. February 2026
TL;DR
- We create datasets of 10 million transitions across 20 Gymnasium environments.
- We fine-tune Qwen-1.7B via supervised learning and obtain 55% average normalized performance.
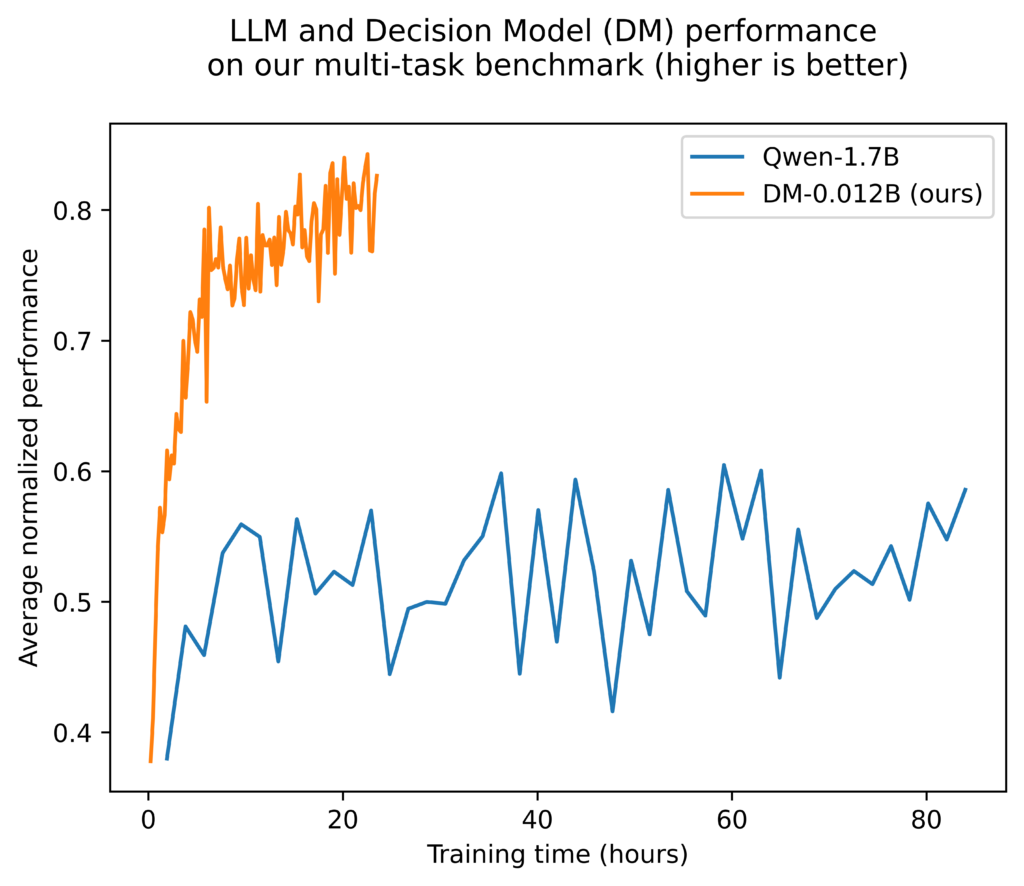
- We compare against an RL-specific transformer model: DM-0.012B, which reaches 81% with 140x less parameters.
- These results suggest that current LLM architectures remain limited for quantitative decision-making, highlighting the need for further research.
1. Motivation
In the era of agentic LLMs, assessing their effectiveness for sequential decision-making remains an open challenge.
We investigate this question in the context of Reinforcement Learning (RL) using 20 simulated environments from the Gymnasium library.
Our goal is to determine whether LLMs can solve relatively simple RL environments, and whether a performance gap persists compared to RL-specific architectures. We focus specifically on behavior cloning from expert data, rather than online RL, to isolate architectural differences.
2. Key Idea
We construct 20 expert datasets, each containing 10 million transitions, resulting in a 200-million-transition multi-task dataset.
We then compare two approaches trained on this shared dataset:
- Supervised fine-tuning of Qwen-1.7B
- Supervised training with an RL-specific transformer model, DM-0.012B
3. Method
3.1 Algorithm
We use imitiation learning on the multi-task dataset.
For a given context length n_transitions_max, each training sample consists of a contiguous sequence of transitions randomly extracted from the dataset, which may span multiple episodes.
Qwen-1.7B specifics
The final training sequence consists of: * The system prompt gives the general instructions, the environment name, the action space and the desired output format. * The list of transitions: The observation (i.e., role=“user”) message contains the observation of the environment, and (except for the very first observation of the sequence) the previous reward/termination/truncation signals. The action (i.e., role=“assistant”) contains the action.
This formulation effectively casts behavior cloning as a next-message prediction problem in a conversational format.
An example with seq_length=3 is given below for the CartPole and HalfCheetah environments:
Cartpole messages
{"content":"You control a CartPole-v1 agent.nYour goal is to maximize the sum of the rewards obtained during an episode (Reinforcement Learning).nFeel free to explore, you are given several episodes to find the best policy.nNote that the environment is autoresetting when an episode is done.nReturn ONLY valid JSON with exactly one key:n{"action":a}nWhere a is an integer in 0..1nNo extra text.n","role":"system"},{"content":"{"observation": [0.0125555, -0.0327935, -0.0235698, -0.033951]}","role":"user"},{"content":"{"action": 0}","role":"assistant"},{"content":"{"observation": [0.0118997, -0.22757, -0.0242488, 0.251203], "reward": 1, "term": False, "trunc": False}","role":"user"},{"content":"{"action": 0}","role":"assistant"},{"content":"{"observation": [0.00734828, -0.422337, -0.0192248, 0.53614], "reward": 1, "term": False, "trunc": False}","role":"user"},{"content":"{"action": 0}","role":"assistant"}
HalfCheetah messages
{"content":"You control a HalfCheetah-v4 agent.nYour goal is to maximize the sum of the rewards obtained during an episode (Reinforcement Learning).nFeel free to explore, you are given several episodes to find the best policy.nNote that the environment is autoresetting when an episode is done.nReturn ONLY valid JSON with exactly one key:n{"action":a}nWhere a is a list of 6 floats formatted as [a0, a1, a2, a3, a4, a5], respecting the lower bound [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0] and upper bound [1.0, 1.0, 1.0, 1.0, 1.0, 1.0]nNo extra text.n","role":"system"},{"content":"{"observation": [0.0731153, -0.0756214, -0.0697146, -0.0345845, -0.0649871, -0.0479404, 0.0472209, 0.0910212, 0.00440165, 0.149537, -0.0911166, 0.167378, -0.0381019, 0.178949, -0.0664392, 0.0603031, -0.000438883]}","role":"user"},{"content":"{"action": [0.956099, -0.0899368, -0.656796, 0.402296, 0.288539, 0.742594]}","role":"assistant"},{"content":"{"observation": [-0.067301, 0.0394335, 0.195527, -0.167817, -0.152994, 0.194582, -0.0451425, 0.227252, 2.54028, -0.873769, -0.797803, 8.49115, 2.09069, -11.8046, 8.71891, 3.08689, -0.533467], "reward": 2.0996, "term": False, "trunc": False}","role":"user"},{"content":"{"action": [0.256653, 0.84912, -5.89574, -0.871725, 0.472961, 0.872767]}","role":"assistant"},{"content":"{"observation": [-0.0947112, -0.0670583, 0.322549, 0.358275, -0.457815, 0.133585, 0.326774, 0.423371, 0.74343, -0.0731082, -2.46382, -0.337217, 11.1515, 1.39821, -5.44028, 7.84672, 6.43616], "reward": 1.01134, "term": False, "trunc": False}","role":"user"},{"content":"{"action": [-0.797737, -0.608111, 0.0463318, -0.401778, 0.853886, 0.887671]}","role":"assistant"}
To respect the training procedure, at evaluation when the length of the episode exceeds n_transitions_max, we keep the system prompt but then remove oldest transitions in a FIFO fashion.
Note that n_transitions_max depends therefore on the specifics of the environment (bigger observation and action spaces lead to more tokens, hence less transitions for a fixed maximum token length). In practice we were able to fit between a few dozen and a few hundred transitions in the context.
DM-0.012B specifics
Our Decision Model follows the Gato tokenization scheme (Reed et al., 2022): continuous values are μ-law encoded and discretized before the embedding lookup, while discrete values are embedded directly.
Observation dimensions (along with the potential previous reward/termination signals) are aggregated into a single embedding, and the same is done for action dimensions. This standard design (e.g., Gallouédec et al., 2024) improves handling of high-dimensional continuous spaces, and enables a larger effective attention window measured in transitions.
The backbone is a 4-layer Llama2-style transformer trained from scratch using cross-entropy loss.
3.2 Training Setup
All experiments are conducted on one node with 8 H200 GPUs.
- Maximum sequence length: 16384 for Qwen-1.7B, 1024 for DM-0.012B
- Batch: 64 for Qwen-1.7B (with gradient accumulation), 24 for DM-0.012B (maximum we were able to fit, no accumulation needed).
3.3 Evaluation Protocol
The results are provided as the normalized expert performance (0%=random, 100%=expert), averaged across the environments. We highlight that both approaches treat the 20 environments as a multi-task dataset, so the same model is used for controlling the 20 environments.
4. Results
We observe that DM-0.012B reaches 81% average normalized performance in less than one day of training.
Qwen-1.7B plateaus at 55% after a similar training duration and shows no further improvement over the next 60 hours.
Despite being trained on the same dataset, the LLM underperforms the RL-specific architecture.
A possible explanation is that text-oriented tokenization and inductive biases are not well suited for precise numerical control, and increasing compute alone does not appear sufficient to close this gap in our setting.
We include below the average normalized performance per environment across the last 10 evaluations, each corresponding to an independent rollout with a different environment seed (note that the performance can exceed 100% because the expert data and performance are obtained by sampling from the optimal policy, while the model evaluations are taking the most probable action). We also bold the best model if the T-test pvalue across the last 10 evaluations is below 0.05.
| env_name | Qwen-1.7B (%) | DM-0.012B (%) |
|---|---|---|
| Acrobot-v1 | 102.21 | 101.56 |
| Ant-v4 | 3.97 | 90.32 |
| BipedalWalker-v3 | -9.33 | 41.28 |
| CartPole-v1 | 100.00 | 97.09 |
| CliffWalking-v0 | 100.36 | 100.50 |
| FrozenLake-v1 | 128.57 | 111.43 |
| HalfCheetah-v4 | 2.21 | 19.97 |
| Hopper-v4 | 2.92 | 57.05 |
| Humanoid-v4 | 0.00 | 43.30 |
| HumanoidStandup-v4 | 0.00 | 69.40 |
| InvertedDoublePendulum-v4 | 22.71 | 73.57 |
| InvertedPendulum-v4 | 48.47 | 89.26 |
| LunarLander-v2 | 88.72 | 96.87 |
| MountainCar-v0 | 105.06 | 79.23 |
| MountainCarContinuous-v0 | 67.40 | 97.35 |
| Pendulum-v1 | 37.07 | 74.75 |
| Pusher-v4 | 94.42 | 98.05 |
| Reacher-v4 | 95.04 | 100.32 |
| Taxi-v3 | 99.80 | 95.13 |
| Walker2d-v4 | 0.41 | 78.59 |
| Average | 54.50 | 80.75 |
We can see that DM-0.012B wins or is equal to Qwen-1.7B in 18/20 training environments, and that for the 2/20 environments where it is beaten its performance was still above 95%.
The largest performance gaps occur in continuous-control MuJoCo environments, where Qwen-1.7B lags far behind in 9 out of 10 tasks, especially in high-dimensional observation and action spaces (e.g., Ant-v4 that has 105 observations and 8 actions).
Note that Qwen-1.7B was not able to perform a full rollout in Humanoid-v4 and HumanoidStandup-v4 (348 observations) as it returned a non-valid JSON after few actions, so we scored a performance of 0% in those environments.
Overall, our results suggest that architecture and tokenization — not just scale — remain critical for sequential decision-making.
5. Real-World Impact
These findings highlight current limitations of LLMs for quantitative decision-making and suggest that specialized foundation models may provide a more effective path for Reinforcement Learning.
In future research, we plan to scale dramatically the number of environments and model capacity, and evaluate transfer to real-world decision-making tasks.
6. Limitations
This study has several limitations:
First, the LLM message construction and tokenization scheme may significantly influence performance. Although we designed a format enabling valid zero-shot interaction, alternative formulations could yield different results.
Second, we cannot exclude the possibility that a larger LLM and/or a much longer training would close the gap, but this is unfortunately not doable for us with our currently available compute capabilities.
Finally, the very algorithm we chose for the comparison (SFT on expert data) could be questioned. We notably would like in future work to swap the history of interactions in the LLM history with an experience-retrieval approach (putting in the context observations from the dataset that are similar to the current observation, along with the optimal dataset actions). Such an approach might indeed leverage more the in-context learning capabilities of LLMs.
References
Gallouédec, Q., Beeching, E., Romac, C., & Dellandréa, E. (2024). Jack of all trades, master of some, a multi-purpose transformer agent. arXiv preprint arXiv:2402.09844.
Reed, S., Zolna, K., Parisotto, E., Colmenarejo, S. G., Novikov, A., Barth-Maron, G., … & De Freitas, N. (2022). A generalist agent. arXiv preprint arXiv:2205.06175.
Appendix
Expert hyperparameters
Experts were trained using Stable-Baselines3, using the following algorithms and hyperparameters. When not mentioned, default hyperparameters were used.
| env_name | algo | hyperparameters | n_timesteps |
|---|---|---|---|
| Acrobot-v1 | DQN | {} | 1000000 |
| Ant-v4 | SAC | {} | 1000000 |
| BipedalWalker-v3 | TQC | {} | 1000000 |
| CartPole-v1 | PPO | {} | 1000000 |
| CliffWalking-v0 | DQN | {} | 1000000 |
| FrozenLake-v1 | PPO | {} | 1000000 |
| HalfCheetah-v4 | SAC | {} | 1000000 |
| Hopper-v4 | SAC | {} | 1000000 |
| Humanoid-v4 | SAC | {} | 1000000 |
| HumanoidStandup-v4 | SAC | {} | 1000000 |
| InvertedDoublePendulum-v4 | SAC | {} | 1000000 |
| InvertedPendulum-v4 | SAC | {} | 1000000 |
| LunarLander-v2 | PPO | {} | 3000000 |
| MountainCar-v0 | DQN | {‘exploration_fraction’: ‘0.02’} | 5000000 |
| MountainCarContinuous-v0 | PPO | {‘batch_size’: ‘256’, ‘clip_range’: ‘0.1’, ‘ent_coef’: ‘0.00429’, ‘gae_lambda’: ‘0.9’, ‘gamma’: ‘0.9999’, ‘learning_rate’: ‘7.77e-05’, ‘max_grad_norm’: ‘5’, ‘n_steps’: ‘8’, ‘use_sde’: ‘true’} | 20000 |
| Pendulum-v1 | TD3 | {} | 1000000 |
| Pusher-v4 | SAC | {} | 1000000 |
| Reacher-v4 | SAC | {} | 1000000 |
| Taxi-v3 | DQN | {} | 3000000 |
| Walker2d-v4 | SAC | {} | 1000000 |
Expert training curves
Training curves are shown below, with a smoothing over the last 50 episodes for trainings exceeding 500 episodes.

Normalized score
normalized = (score − random) / (expert − random)
Code acknowledgement
We built on the great repository https://github.com/PrimeIntellect-ai/prime-rl for Qwen-1.7B fine-tuning.
We used https://github.com/DLR-RM/rl-baselines3-zoo for finding expert hyperparameters for some environments exhibiting strong hyparameter sensitivity.